Eric fleming


My name is Eric Fleming, and I specialize in the application of artificial intelligence to support and enhance scientific research. With a background in computer science and data-driven methodologies, I focus on building intelligent systems that accelerate discovery, improve research accuracy, and streamline complex data analysis across diverse scientific domains.
My work involves developing and deploying AI-powered tools for literature mining, hypothesis generation, experiment planning, and automated data interpretation. I have worked with machine learning models, natural language processing (NLP), and knowledge graph construction to assist researchers in navigating vast information spaces and uncovering novel insights.
I am passionate about transforming the way science is conducted by integrating intelligent assistants that empower researchers, reduce manual effort, and increase the reproducibility and transparency of research. My goal is to make scientific inquiry faster, smarter, and more collaborative through the responsible use of AI technologies.
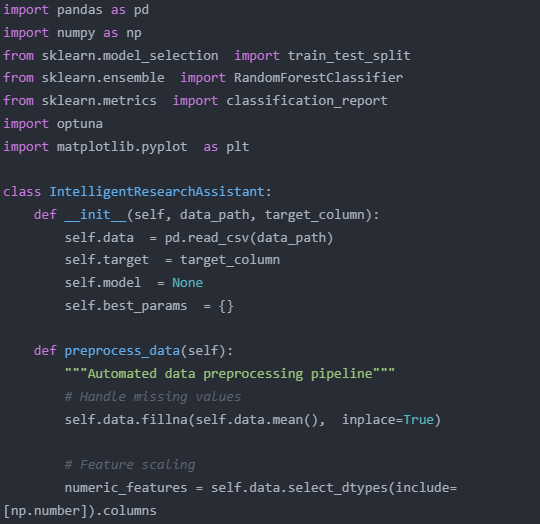
Main Functional Module Descriptions:
Data Preprocessing (preprocess_data)
Automatically handles missing values.
Standardizes features.
Automatically identifies numerical features.
Model Optimization (optimize_model)
Uses Optuna for hyperparameter optimization.
Supports random forest parameter tuning.
Automatically evaluates models using cross-validation.
Report Generation (generate_report)
Visualizes feature importance.
Generates classification reports.
Saves results as files.
Scientific research requires nuanced understanding of domain-specific language, formal structures of argumentation, and interdisciplinary synthesis. Publicly available GPT-3.5 or even general GPT-4 models lack the fine-grained calibration to accurately interpret complex hypotheses, detect logical fallacies, or assist in experimental critique. Fine-tuning GPT-4 using structured prompts and annotated scientific corpora will enable it to reason within disciplinary conventions, support knowledge transfer across domains, and enhance the credibility of its generated content.Moreover, many scientific queries involve evolving jargon, multimodal data references, or structured experiment protocols—none of which can be handled reliably by unmodified GPT-3.5. Fine-tuning is essential to bridge the semantic gap between general LLM behavior and the rigorous expectations of the scientific process.